Training AlphaZero for 700,000 steps. Elo ratings were computed from
Por um escritor misterioso
Descrição

Is DeepMind's new reinforcement learning system a step toward general AI? - TechTalks
When Alpha Zero is making seemingly bizarre moves in chess is it actually predicting what its opponent will do (calculating possibilities), or is it setting up its own attack/defense based on positional

A summary of the DeepMind's general reinforcement learning algorithm, AlphaZero, by Umer Hasan

From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

AlphaZero really is that good

AlphaZero - Stockfish: French Defense, Classical Variation, Steinitz Variation (C14) : r/chess
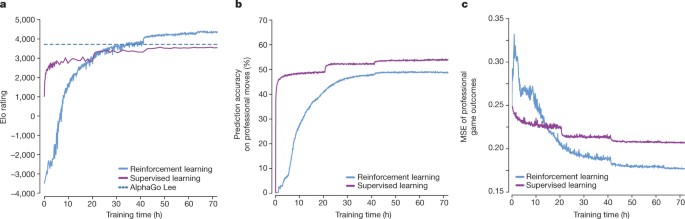
Mastering the game of Go without human knowledge

DeepMind's AlphaZero beats state-of-the-art chess and shogi game engines

DeepMind's AlphaZero beats state-of-the-art chess and shogi game engines

The future is here – AlphaZero learns chess
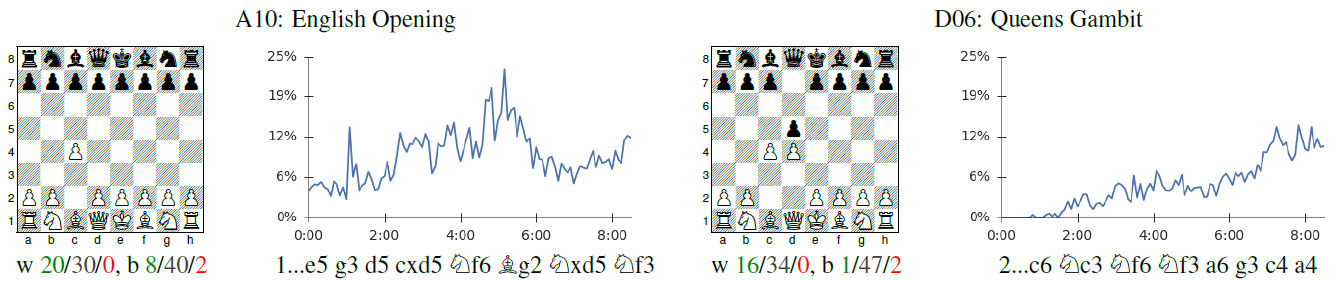
The future is here – AlphaZero learns chess

Figure 1 from Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
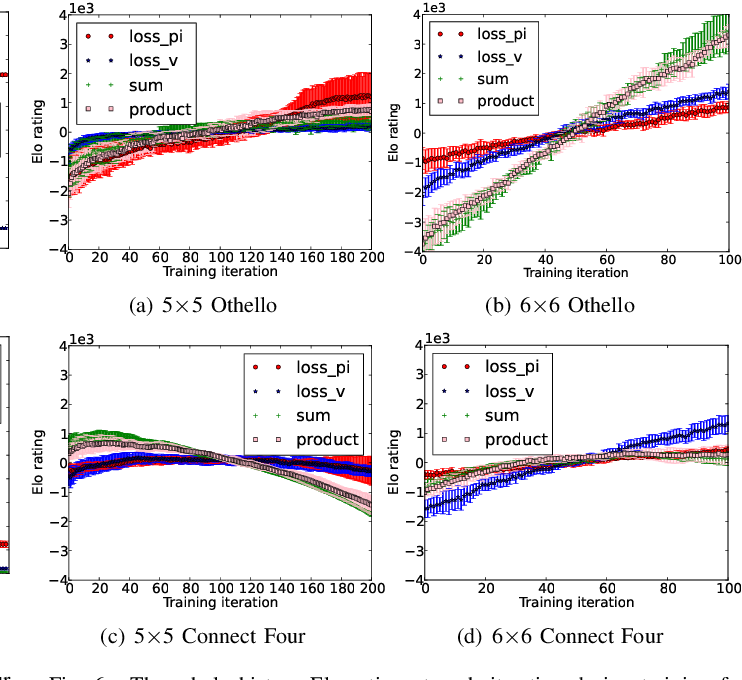
Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self-play

AlphaZero really is that good
de
por adulto (o preço varia de acordo com o tamanho do grupo)