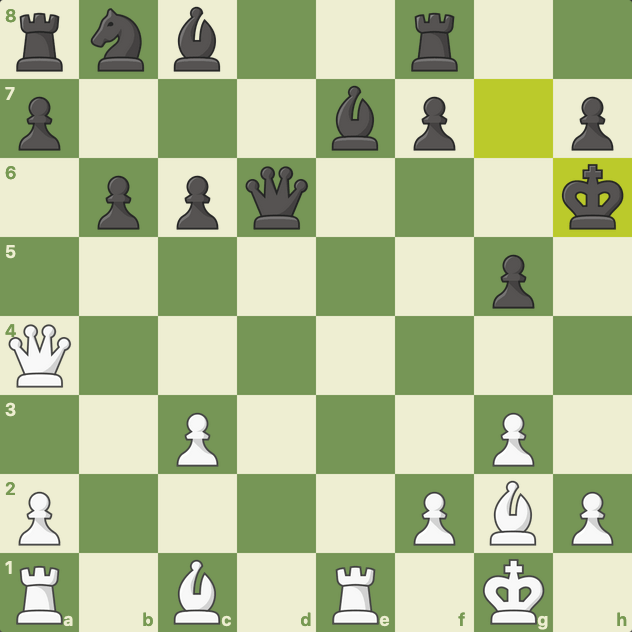
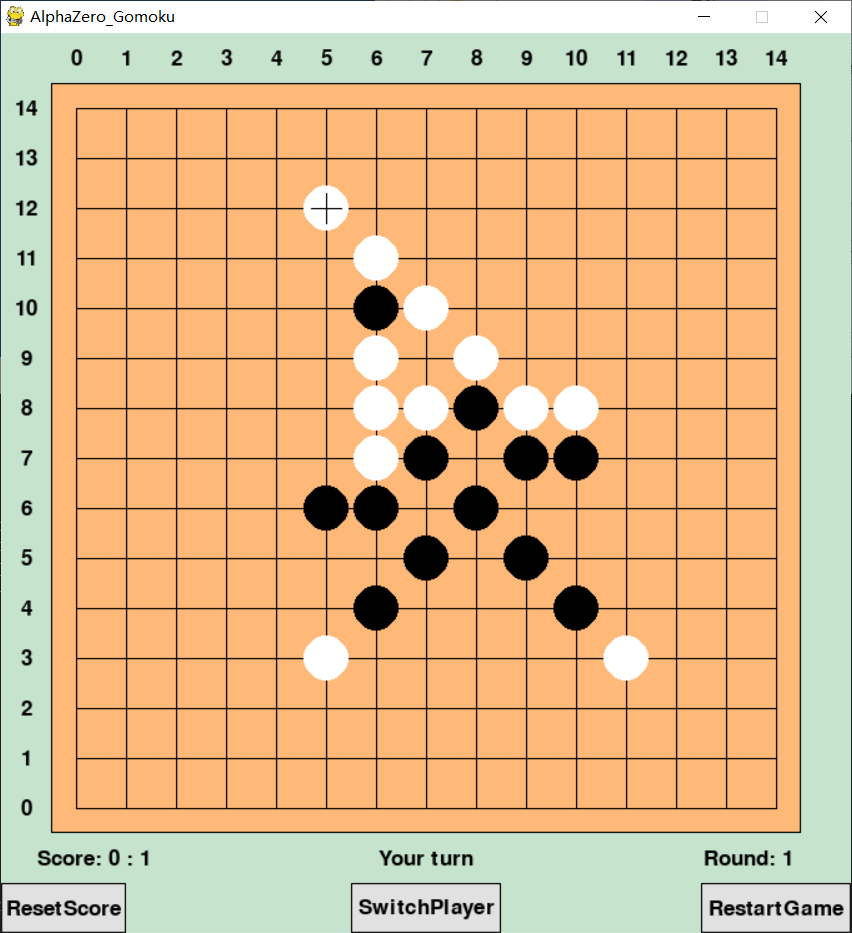
The average number of unique states visited by AlphaZero and Go-Exploit
Por um escritor misterioso
Descrição
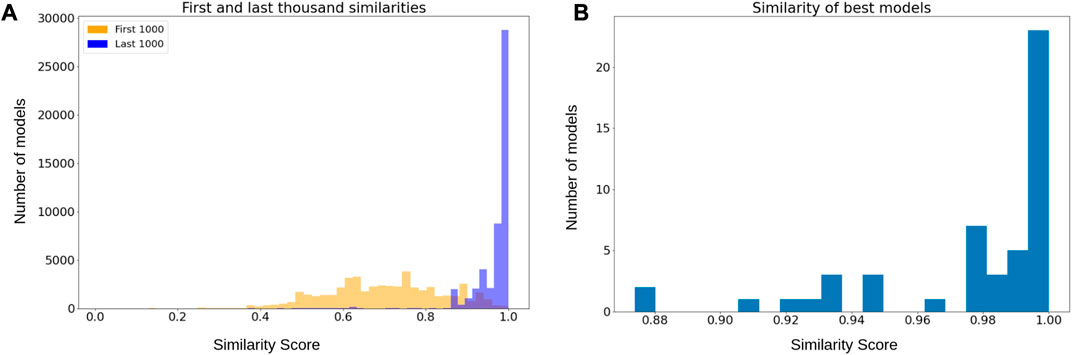
Frontiers Automatic mechanistic inference from large families of Boolean models generated by Monte Carlo tree search

Science Cast

AlphaZero: A General Reinforcement Learning Algorithm that Masters Chess, Shogi and Go through Self-Play

The average number of unique states visited by AlphaZero and Go-Exploit

Targeted Search Control in AlphaZero for Effective Policy Improvement – arXiv Vanity

Spatial state-action features for general games - ScienceDirect
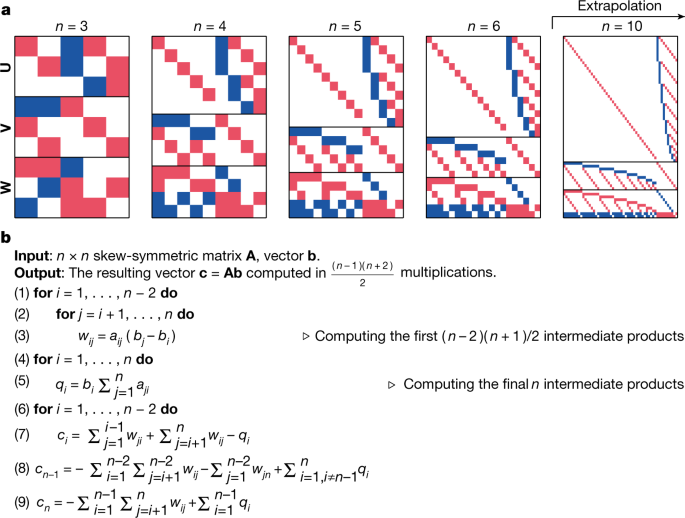
Discovering faster matrix multiplication algorithms with reinforcement learning

Issue 20, Volume 143 (March 7, 2023) by The Varsity - Issuu

AlphaGo Zero: Mastering the Game of Go Without Human Knowledge
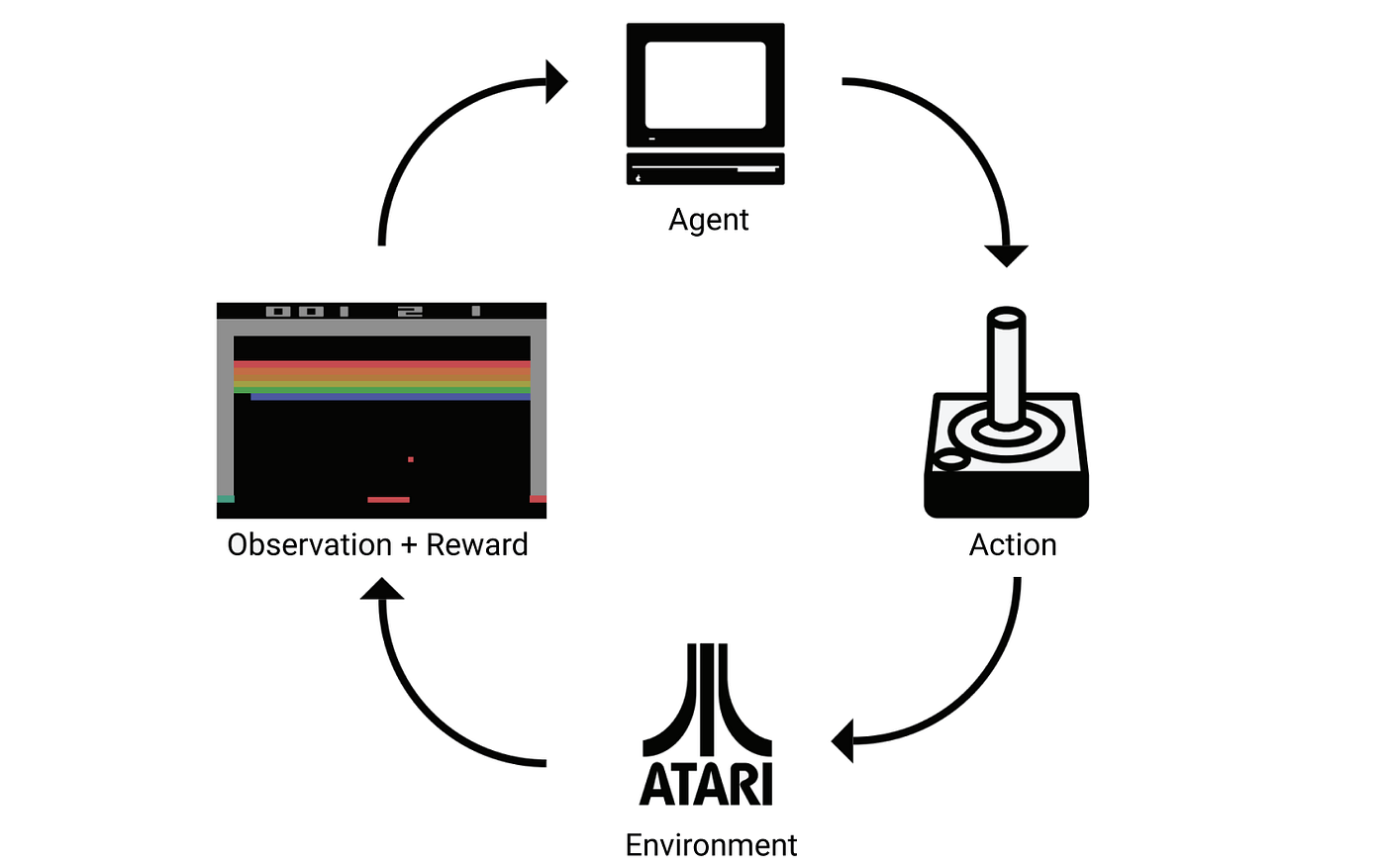
What is Reinforcement Learning anyways?, by Martin Klissarov, Apache MXNet
The average number of unique states visited by AlphaZero and Go-Exploit
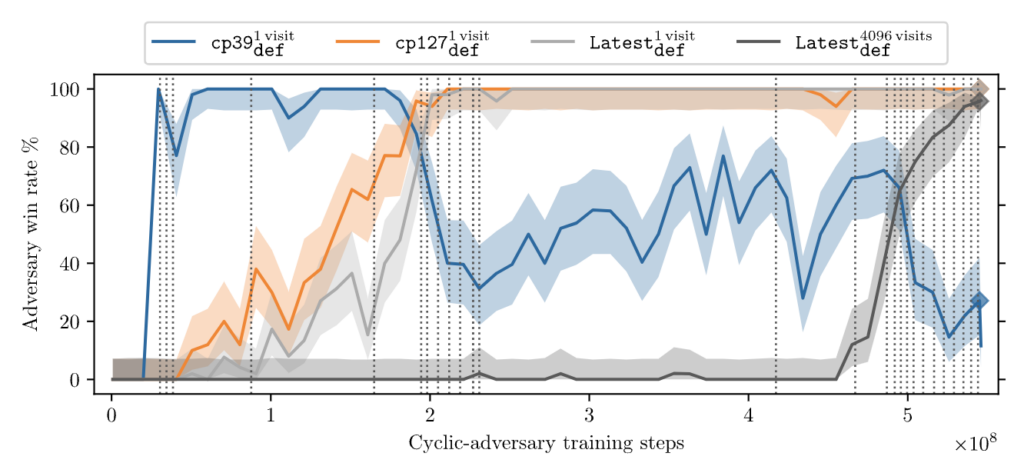
Even Superhuman Go AIs Have Surprising Failures Modes – Center for Human-Compatible Artificial Intelligence
de
por adulto (o preço varia de acordo com o tamanho do grupo)